|
|
|
|
|
|
|
|
|
|
Presented at the 7th International Conference on Computer Vision & Image Processing 20221 Sardar Vallabhbhai National Institute of Technology (SVNIT), Surat, India. 2 Norwegian University of Science and Technology (NTNU), Gjøvik, Norway. |
|
|
|

|
|
|
|
|
|
|
|
|
|
|
Presented at the 7th International Conference on Computer Vision & Image Processing 20221 Sardar Vallabhbhai National Institute of Technology (SVNIT), Surat, India. 2 Norwegian University of Science and Technology (NTNU), Gjøvik, Norway. |
|
|
|
|
|
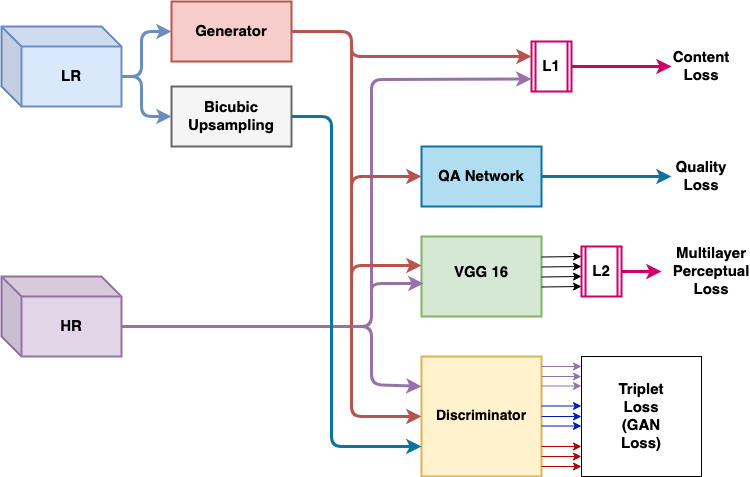
We tackle this problem by proposing a Triplet loss-based GAN for Real-world Super-Resolution (SRTGAN) , which exploits the information from LR image through triplet loss formulation and improves the adversary and perceptual quality of generated images. The below images show true LR and corresponding bicubic downsampled LR image from ground truth HR. 

|
|
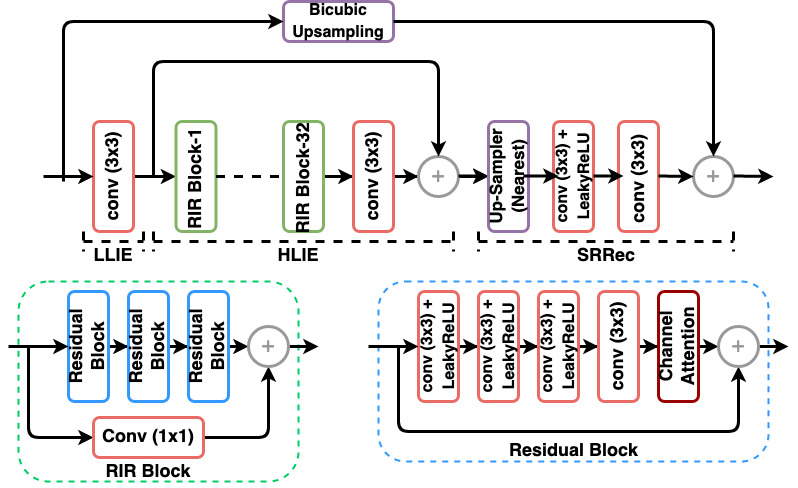
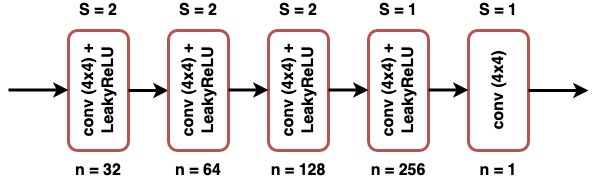
| Our proposed framework consists of 2 major components:
|
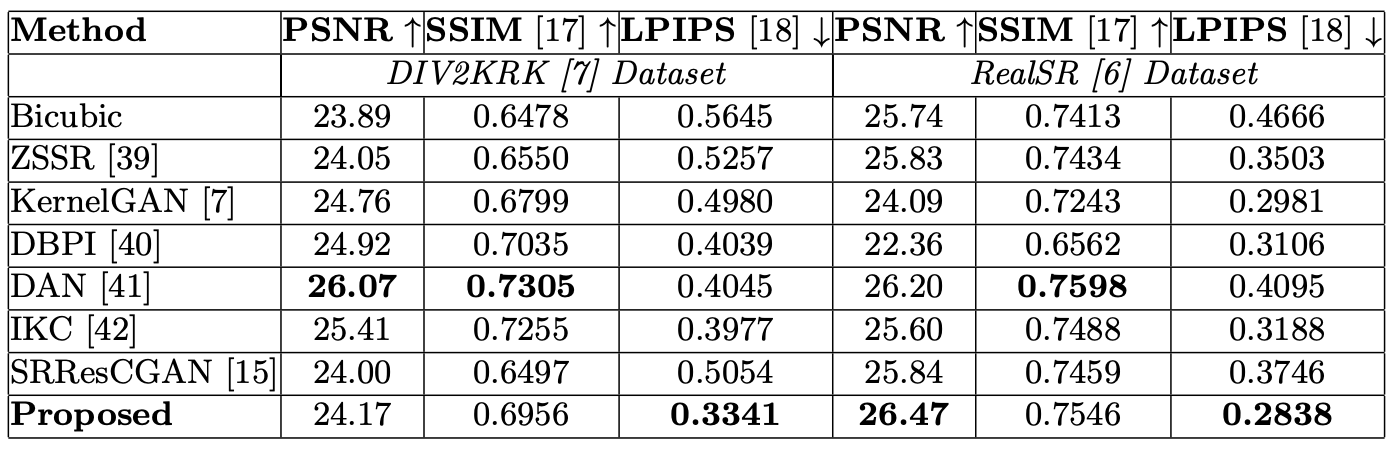
|



|
If you have any questions, please reach out to any of the above mentioned authors.